Performance Review of the New "Read It Later"
Read it Later is an online tool and app that allows you to save the "one read wonders" that you find on the web for another time. I use this service frequently, since I'm often checking up on Twitter or Google+ on my phone and seeing posts that I want to read, but that I don't have time to read at that time. It's easy to add a URL to Read it Later and pull it up on my desktop at home. Overall it's a great service, and free.
When I started using Read it Later it had a really simple web interface, with no frills or fancy animations. This made for a fast, but not particularly sophisticated product.
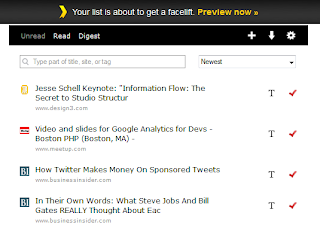
Read it Later is currently trying out a new and improved web interface that gives larger previews of your articles (including thumbnails), easier navigation and action menus, better use of the available screen real estate, nice animations when you mark things as read, and generally a cleaner and more modern look (among other improvements).
 Overall I think it's a big step up in terms of usability and design, with one notable exception. In the past when you clicked on articles you went straight to the original page. In the new version, these links default to a page on readitlaterlist.com that extracts the content from the original URL and serves it on Read it Later's domain. This works well for pure text articles, but I've found that videos and pictures can get lost or moved around, making for a worse experience than the original page. I don't like having to click twice to get back to it, so I really hope they add a button to "view original" on the main list page.
Overall I think it's a big step up in terms of usability and design, with one notable exception. In the past when you clicked on articles you went straight to the original page. In the new version, these links default to a page on readitlaterlist.com that extracts the content from the original URL and serves it on Read it Later's domain. This works well for pure text articles, but I've found that videos and pictures can get lost or moved around, making for a worse experience than the original page. I don't like having to click twice to get back to it, so I really hope they add a button to "view original" on the main list page.
The other difference in the new view is that it is much slower. Here is a comparison between the two views using YSlow and Google PageSpeed (higher is better, scores are out of 100).
So what happened? Why did the performance get so much worse from the old version to the new? In general, Read it Later added a bunch of new functionality without focusing on how it would affect performance. Luckily there are a few really simple things that Read it Later could do to raise their scores and make their site faster:
Combining these images into a sprite would easily eliminate 11 HTTP requests.
The page is also getting hit for the favicons it is trying to download. Read it Later is trying to download the favicon for the parent domain of every article and display it at the bottom of the article block. However it appears that most of these favicons are not downloading successfully, so I just see the default blank page icon.

The problem is that Read it Later is serving each of these favicons from a unique URL (like http://img.readitlater.com/i/businessinsider.com/favicon.ico?f=fi and http://img.readitlater.com/i/meetup.com/favicon.ico?f=fi). This means that I make an extra request for every favicon, even though many of them are identical. Read it Later should either stop trying to download these if they are going fail to do it successfully, or find a way to detect that the download failed and serve the blank favicon from a consistent URL.
The last thing I'll mention here is the use of JavaScript. The new view is much more interactive and adds a lot of functionality. Unfortunately this comes with a price: 21 JS files are being loaded on the page. Many of these are extremely small files, on my page there are seven of them that are under 1KB. Worst of all, these files are all loaded in the head of the document, where they block the rendering of the page. Read it Later would get a huge performance boost out of combining these files and moving as much of the JS to the bottom of the page as possible. If they wanted to dive deeper they could find ways of loading the JavaScript asynchronously. We had a great talk about JavaScript loading techniques at my Meetup group in Boston recently by Nicholas Zakas - maybe the developers at Read it Later should check out the slides and video.
I love seeing redesigns that make for a better user experience and add functionality, but not at the expense of speed. With about a day of work Read it Later could dramatically improve the performance of their new interface, and I hope they take the time to do this before launching it for all of their users.
When I started using Read it Later it had a really simple web interface, with no frills or fancy animations. This made for a fast, but not particularly sophisticated product.

Read it Later is currently trying out a new and improved web interface that gives larger previews of your articles (including thumbnails), easier navigation and action menus, better use of the available screen real estate, nice animations when you mark things as read, and generally a cleaner and more modern look (among other improvements).

The other difference in the new view is that it is much slower. Here is a comparison between the two views using YSlow and Google PageSpeed (higher is better, scores are out of 100).
| Version | YSlow | PageSpeed |
|---|---|---|
| Old | 84 | 72 |
| New | 74 | 68 |
So what happened? Why did the performance get so much worse from the old version to the new? In general, Read it Later added a bunch of new functionality without focusing on how it would affect performance. Luckily there are a few really simple things that Read it Later could do to raise their scores and make their site faster:
- Remove ETags - In almost all cases these are completely unnecessary, and they just add data to the requests on the page. It is a simple server configuration change to remove them.
- Combine CSS files - I see six small CSS files loaded in the head of the page, right next to each other. It should be trivial to combine these into one file, and it would definitely have a positive impact on performance.
- Add Expires Headers - None of the images on my view have any expires header at all, which means that my browser is going to request them every single time I load the page. Adding these headers would mean that on subsequent visits to my list I wouldn't have to fetch those images again.
- Sprite background images - There are a ton of icons on the page that are served from a Read it Later domain but are NOT in a sprite:
http://readitlaterlist.com/a/i/drop_down.png
http://readitlaterlist.com/a/i/drop_up.png
http://readitlaterlist.com/a/i/footer_i_edit.png
http://readitlaterlist.com/a/i/footer_i_left.png
http://readitlaterlist.com/a/i/footer_i_tag.png
http://readitlaterlist.com/a/i/header_carrot.png
http://readitlaterlist.com/a/i/pagenav_grid.png
http://readitlaterlist.com/a/i/pagenav_list.png
http://readitlaterlist.com/a/i/pagenav_selected.png
http://readitlaterlist.com/a/i/searchbar_icon.png
http://readitlaterlist.com/a/i/toolbar_article.png
http://readitlaterlist.com/a/i/toolbar_image.png
Combining these images into a sprite would easily eliminate 11 HTTP requests.
The page is also getting hit for the favicons it is trying to download. Read it Later is trying to download the favicon for the parent domain of every article and display it at the bottom of the article block. However it appears that most of these favicons are not downloading successfully, so I just see the default blank page icon.

The problem is that Read it Later is serving each of these favicons from a unique URL (like http://img.readitlater.com/i/businessinsider.com/favicon.ico?f=fi and http://img.readitlater.com/i/meetup.com/favicon.ico?f=fi). This means that I make an extra request for every favicon, even though many of them are identical. Read it Later should either stop trying to download these if they are going fail to do it successfully, or find a way to detect that the download failed and serve the blank favicon from a consistent URL.
The last thing I'll mention here is the use of JavaScript. The new view is much more interactive and adds a lot of functionality. Unfortunately this comes with a price: 21 JS files are being loaded on the page. Many of these are extremely small files, on my page there are seven of them that are under 1KB. Worst of all, these files are all loaded in the head of the document, where they block the rendering of the page. Read it Later would get a huge performance boost out of combining these files and moving as much of the JS to the bottom of the page as possible. If they wanted to dive deeper they could find ways of loading the JavaScript asynchronously. We had a great talk about JavaScript loading techniques at my Meetup group in Boston recently by Nicholas Zakas - maybe the developers at Read it Later should check out the slides and video.
I love seeing redesigns that make for a better user experience and add functionality, but not at the expense of speed. With about a day of work Read it Later could dramatically improve the performance of their new interface, and I hope they take the time to do this before launching it for all of their users.


Just sent you a tweet showing you a performance test on Mobile. It's very fast on Sprint. There home page has less content on it than Google's mobile home page and with one "read it later" page in my account the web page loaded in <3.5 seconds which is really fast.
ReplyDeletePeter
Their homepage is definitely fast, but the queue is where things start to bog down. I took a look at your test and it seems like you are hitting the old layout. The new one is at http://readitlaterlist.com/a/queue/. Also is your test able to login?
ReplyDelete